Why Detecting AI Writing After the Fact Is So Hard (and What Educators Can Do Instead)
Introduction
Over the past two years, artificial intelligence has moved from the background of education to the foreground. Large language models (LLMs) such as ChatGPT, Gemini, and Claude are now able to produce essays, reports, and even research papers that look remarkably human. For teachers and administrators, an increasingly pressing question has become: can we reliably tell when a student hands in AI-generated work?
A growing number of commercial tools promise to do just that. Services like GPTZero, Copyleaks, Writer, and others advertise that they can identify machine-written text and safeguard academic integrity. Yet, despite their popularity, the evidence for their effectiveness is not promising. Both research and classroom experience show that post-hoc detection of AI writing faces deep technical, theoretical, and practical challenges. At best, these tools offer a probability judgment; at worst, they mislabel genuine student work.
This article surveys recent research on AI detection, showing why the problem is harder than many assume — and why educators may need to consider alternatives that focus less on catching students after the fact and more on supporting integrity during the writing process.
The Current Landscape of AI Detection
AI detectors typically fall into a few categories. Some rely on supervised classifiers trained to distinguish between human and AI text. Others use linguistic or statistical fingerprints (for example, how often certain words or structures appear). More ambitious approaches include retrieval-based methods (checking whether passages appear verbatim in model outputs) and watermarking (embedding hidden signals into generated text).
These methods can show promising results in controlled tests. For example, classifiers sometimes report 85–95% accuracy in differentiating between machine and human prose. Yet such numbers often collapse when exposed to real-world variation: different models, subject domains, languages, and styles. And because AI systems themselves are improving so quickly, any detection method has a very short shelf life before it is outdated.
Theoretical and Technical Limits
Some of the deepest challenges are not just practical but theoretical.
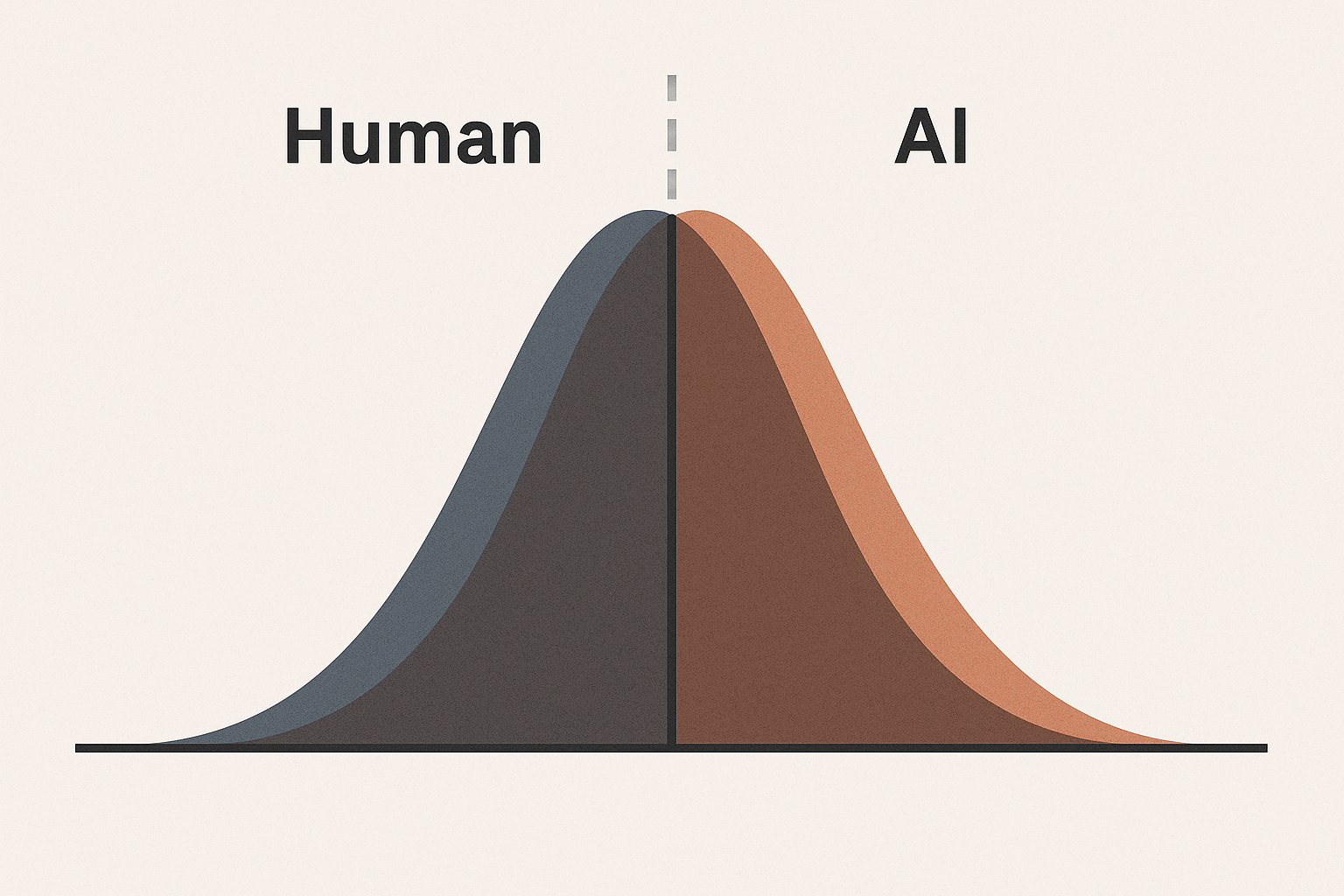
A 2024 survey on detection, Decoding the AI Pen (arXiv), highlights a fundamental problem: as LLMs get closer to human-like distribution patterns, the ability to distinguish between human and AI text approaches the limits of probability. When two distributions overlap almost completely, even the best detector can do only slightly better than random guessing.
The same paper also points to adversarial vulnerabilities. Simple tricks such as paraphrasing, re-ordering, or intentionally “dirtying” text with spelling mistakes can fool many detectors. Spoofing and data poisoning attacks further erode reliability. Watermarking — often described as the most reliable solution — is itself constrained: robust schemes are impossible without degrading text quality, and watermark signals disappear if text is lightly edited.
These limits are reinforced in a 2024 Patterns article, Perfect detection of computer-generated text faces fundamental challenges. The authors argue that “perfect” detection is not just hard but impossible. Detection methods and generation models are locked in an arms race: every time detectors improve, AI systems learn to evade them. As a result, detection tools may only provide a temporary edge before they are rendered obsolete. The paper suggests shifting focus away from purely technical solutions and toward ethical frameworks and institutional guidelines for academic integrity.
Empirical Evidence: Detection in Practice
Laboratory tests often paint a mixed picture of detection efficacy.
A 2023 study in the International Journal for Educational Integrity tested five well-known tools — OpenAI Classifier, Writer, Copyleaks, GPTZero, and CrossPlag — on a set of academic abstracts. The findings were clear: the tools performed reasonably well on GPT-3.5 outputs but struggled with GPT-4, producing more false negatives. Even more concerning were false positives, where genuine human writing was flagged as AI. For teachers, this means that relying too heavily on these tools risks wrongly accusing students of misconduct.
Research at Penn State (2024) sheds further light on the human side of the problem. In controlled experiments, people asked to identify AI text did only slightly better than chance: about 53% accuracy, essentially a coin toss. Even when trained, human evaluators found it almost impossible to reliably distinguish AI writing. Detectors did better — often achieving 85–95% accuracy — but these results depend on narrow benchmarks. Once models like GPT-4 or Gemini are introduced, performance declines, and detectors function as opaque “black boxes” whose judgments are hard to interpret.
Some feature-based approaches show promise in highly specific domains. A 2023 PMC study on chemistry writing used an XGBoost classifier with 20 text features and achieved 98–100% accuracy when distinguishing AI-generated chemistry abstracts from human ones. Yet the study also reported difficulties in the opposite direction: because human writing styles are so diverse, the classifier misidentified some authentic articles. Real-world student writing is far more varied and messy than curated journal prose, making false positives even more likely.
Taken together, these findings show a common pattern: detection looks strongest in narrow, controlled settings but falters in the wild. In practice, the mix of different writing styles, evolving models, and deliberate attempts at evasion quickly overwhelm the detectors.
Recent Surveys and Broader Implications
A 2025 survey in the Journal of Artificial Intelligence Research (JAIR), Detecting AI-Generated Text: Factors Influencing Detectability with Current Methods, synthesizes much of the field. It confirms that detectability is highly dependent on model sophistication, with newer models systematically eroding detector performance. The survey also points out that datasets are often limited to English prose and a handful of subject areas, leaving large gaps in multilingual and domain-specific testing.
The implications go well beyond classrooms. Detection challenges affect journalism, law, scientific publishing, and government communication. If LLMs can generate human-like disinformation, but detectors cannot keep up, society faces a much broader integrity crisis. The survey calls for further research, but it also acknowledges that technical progress alone may not be sufficient.
What This Means for Education
For teachers and administrators, these research findings present a dilemma. On one hand, institutions want to preserve academic integrity and ensure that students are actually learning. On the other, over-reliance on weak detection tools risks undermining fairness.
False positives can unfairly penalize students, damaging trust and even leading to legal disputes. False negatives can give educators a false sense of security. And because detection tools are not standardized, two different systems might produce opposite judgments on the same essay.
The Patterns paper is blunt: educators should not expect perfect technological solutions. Instead, they should combine vigilance with cultural and ethical responses. This means developing clear policies, teaching students about the responsible use of AI, and fostering an environment where integrity is expected and valued.
Alternatives: Process-Based Approaches
If post-hoc detection of finished text is unreliable, what alternatives exist? One promising direction is to shift the focus from product to process.
Instead of trying to analyze a completed essay, educators can look at how the essay was written. Process-based approaches include:
- Draft history tracking, which records how a document evolved over time.
- Keystroke or edit logging, which shows whether a student wrote steadily or pasted large chunks at once.
- Interactive writing environments, where students compose directly in platforms that preserve revision data.
These methods are harder to fake. Even if a student uses AI for assistance, the writing process will look very different from genuine human drafting. Tools like PaperMind are built with this philosophy in mind. Rather than guessing whether a finished essay was written by AI, PaperMind tracks the writing process itself — logging edits, drafts, and revisions. This provides teachers with transparent insight into how student work was produced, reducing reliance on brittle after-the-fact detectors.
Just as plagiarism detection evolved from crude keyword matching to originality reports and source analysis, AI-era integrity may require tools that make the writing process more transparent. Rather than playing a cat-and-mouse game of “catching” students, educators can design environments where authentic work naturally shines through.
Conclusion
The research consensus is clear: detecting AI-generated writing after the fact is a problem with hard limits. As LLMs grow more sophisticated, their outputs overlap so closely with human writing that even the best tools struggle to do better than chance. Real-world testing shows high false positive and false negative rates, undermining fairness and reliability. And because detectors and generators evolve together, each breakthrough is temporary.
This does not mean that educators are powerless. It means the challenge must be reframed. Instead of relying on brittle tools to separate human from machine, we can design classrooms, policies, and technologies that emphasize process, support integrity, and make authentic work the easiest path forward.
Instead of trying to find the “ghost in the machine,” educators can adopt tools that aim to make integrity a natural outcome, without giving up on the essay entirely. Platforms like PaperMind, for example, help teachers see the full writing process, providing a fairer and more reliable way to support authentic student work.